System Performance
Postmortem
Date of Incident: 08/15/2019
Time/Date Incident Started: 08/15/2019, 12:18 am EDT
Time/Date Stability Restored: 08/15/2019, 12:41 pm EDT
Time/Date Incident Resolved: 08/15/2019, 01:03 pm EDT
Users Impacted: All Active Users
Frequency: Sustained
Impact: Major
Incident description:
Network routing issue resulting in a Gateway Time-out error. Users were unable to access the platform.
Root Cause Analysis:
There was a network routing issue that occurred on one of our core network routing appliances (Cisco CSR). During this time, we encountered a simultaneous failure of two interfaces supporting our site-to-site tunnels.
ServiceChannel implements connectivity between cloud providers using VPN tunnels. In our AWS-Azure connection, we interconnect using four VPN tunnels, where each CSR terminates two VPN tunnels. In this active-active configuration, only one tunnel connection is necessary to carry traffic between AWS and Azure environments, but three additional redundant paths are available in the event of a tunnel or hardware failure.
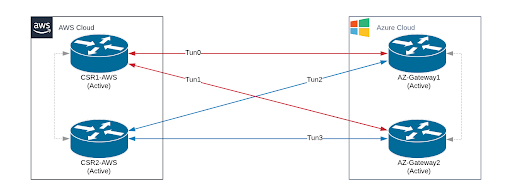 In the event of a tunnel failure, traffic continues to be carried by the other tunnel in the active node in the CSR pair. In the event of the CSR hardware failing or the failure of both tunnels on the active node in the CSR pair, traffic fails over to the other CSR.
In the event of a tunnel failure, traffic continues to be carried by the other tunnel in the active node in the CSR pair. In the event of the CSR hardware failing or the failure of both tunnels on the active node in the CSR pair, traffic fails over to the other CSR.
During this incident, both tunnels on the active CSR at AWS failed simultaneously, so the CSR was marked as failed, and traffic was automatically switched to the other CSR. The link between the cloud datacenters was restored.
Unfortunately, shortly after the successful failover, the Dead Peer Detection (DPD) mechanism used by Cisco CSRs triggered a key exchange event using the ISAKMP protocol. This renegotiation triggered a full tunnel restart and route repopulation using the BGP protocol. This process took approximately 15 minutes, resulting in the downtime event.
While our failover mechanism worked exactly as it was designed, this failover event took more time than is desirable.
Actions Taken:
- Identified the affected CSR instance
- Observed failover of tunnels
- Monitored to confirm that the secondary device was taking traffic
- Restored the failed CSR pair to service
Mitigation Measures:
- Increased monitoring sensitivity to alert operational staff to traffic issues between AWS and Azure infrastructure more quickly.
- Review failover mechanism to reduce failover time in the event of a DPD-initiated ISAKMP renegotiation.
Resolved
...
We have identified a network connectivity issue between our datacenters. Our engineers are implementing a fix.
...
After implementing a fix, services are returning to normal. We will continue to monitor.
...
All services are confirmed running as expected. We consider this incident to be resolved.